
SLIDE 1
1
These slides may be freely used, distributed, and incorporated into other works.
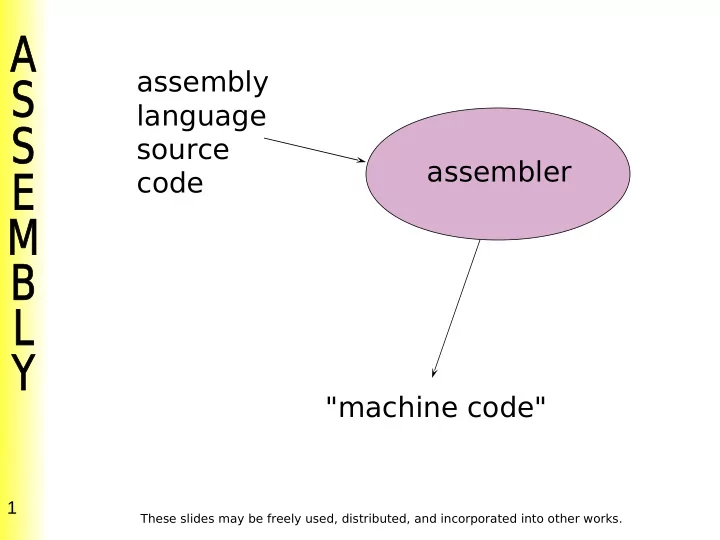
assembly language source assembler code "machine code" - - PowerPoint PPT Presentation
assembly language source assembler code "machine code" 1 These slides may be freely used, distributed, and incorporated into other works. To execute a program: 1 put the "machine code" into memory 2 jal __start (the OS
1
These slides may be freely used, distributed, and incorporated into other works.
2
These slides may be freely used, distributed, and incorporated into other works.
3
These slides may be freely used, distributed, and incorporated into other works.
1.
2.
3.
4
These slides may be freely used, distributed, and incorporated into other works.
5
These slides may be freely used, distributed, and incorporated into other works.
6
These slides may be freely used, distributed, and incorporated into other works.
7
These slides may be freely used, distributed, and incorporated into other works.
quotient remainder
8
These slides may be freely used, distributed, and incorporated into other works.
9
These slides may be freely used, distributed, and incorporated into other works.
HI LO X
10
These slides may be freely used, distributed, and incorporated into other works.
11
These slides may be freely used, distributed, and incorporated into other works.
12
These slides may be freely used, distributed, and incorporated into other works.
13
These slides may be freely used, distributed, and incorporated into other works.
14
These slides may be freely used, distributed, and incorporated into other works.
15
These slides may be freely used, distributed, and incorporated into other works.
requires the address assigned for
every address is assigned by the
16 16 32
16
These slides may be freely used, distributed, and incorporated into other works.
17
These slides may be freely used, distributed, and incorporated into other works.
MS part 000 . . . 0
LS part 000 . . . 0
LS part MS part
18
These slides may be freely used, distributed, and incorporated into other works.
19
These slides may be freely used, distributed, and incorporated into other works.
20
These slides may be freely used, distributed, and incorporated into other works.
16 bits
21
These slides may be freely used, distributed, and incorporated into other works.
16
value 12
22
These slides may be freely used, distributed, and incorporated into other works.
23
These slides may be freely used, distributed, and incorporated into other works.
24
These slides may be freely used, distributed, and incorporated into other works.
first pass:
(MIPS-only) MAL TAL synthesis assign all addresses
second pass:
produce all machine code
Keep a list of instructions that cannot
25
These slides may be freely used, distributed, and incorporated into other works.
26
These slides may be freely used, distributed, and incorporated into other works.
As the assembler works on the source
Scanner (a SW module)
breaks a set of characters into significant
often, tokens are separated by white space
27
These slides may be freely used, distributed, and incorporated into other works.
28
These slides may be freely used, distributed, and incorporated into other works.
The assembler places items into these 2
Use starting addresses of
The variable internal to the assembler
29
These slides may be freely used, distributed, and incorporated into other works.
30
These slides may be freely used, distributed, and incorporated into other works.
31
These slides may be freely used, distributed, and incorporated into other works.
32
These slides may be freely used, distributed, and incorporated into other works.
16
33
These slides may be freely used, distributed, and incorporated into other works.
34
These slides may be freely used, distributed, and incorporated into other works.
16
35
These slides may be freely used, distributed, and incorporated into other works.
36
These slides may be freely used, distributed, and incorporated into other works.
37
These slides may be freely used, distributed, and incorporated into other works.
16
38
These slides may be freely used, distributed, and incorporated into other works.
39
These slides may be freely used, distributed, and incorporated into other works.
40
These slides may be freely used, distributed, and incorporated into other works.
01001 01010 Rd
41
These slides may be freely used, distributed, and incorporated into other works.
42
These slides may be freely used, distributed, and incorporated into other works.
43
These slides may be freely used, distributed, and incorporated into other works.
44
These slides may be freely used, distributed, and incorporated into other works.
45
These slides may be freely used, distributed, and incorporated into other works.
00000 00000
46
These slides may be freely used, distributed, and incorporated into other works.
47
These slides may be freely used, distributed, and incorporated into other works.
48
These slides may be freely used, distributed, and incorporated into other works.
(can't do this in unsigned, so convert to 2's complement)
additive inverse of
49
These slides may be freely used, distributed, and incorporated into other works.
50
These slides may be freely used, distributed, and incorporated into other works.
51
These slides may be freely used, distributed, and incorporated into other works.
52
These slides may be freely used, distributed, and incorporated into other works.
eliminated 16 bit I field of instruction
53
These slides may be freely used, distributed, and incorporated into other works.
54
These slides may be freely used, distributed, and incorporated into other works.
55
These slides may be freely used, distributed, and incorporated into other works.
56
These slides may be freely used, distributed, and incorporated into other works.
57
These slides may be freely used, distributed, and incorporated into other works.
00010 00000
16
58
These slides may be freely used, distributed, and incorporated into other works.
59
These slides may be freely used, distributed, and incorporated into other works.
60
These slides may be freely used, distributed, and incorporated into other works.
61
These slides may be freely used, distributed, and incorporated into other works.
0000 10
most of an address 26 bits 6 bits
62
These slides may be freely used, distributed, and incorporated into other works.
0000 10
most of an address
63
These slides may be freely used, distributed, and incorporated into other works.
1 16th of memory
16th of memory are all of the form
26 bits fixed
64
These slides may be freely used, distributed, and incorporated into other works.
1 16th of memory ?
65
These slides may be freely used, distributed, and incorporated into other works.
31 28 00
26 bits of L1
66
These slides may be freely used, distributed, and incorporated into other works.