
SLIDE 1
HMMs for Speech
1
HMMs for Speech 1 Transitions with Bigrams 2 Decoding Finding - - PowerPoint PPT Presentation
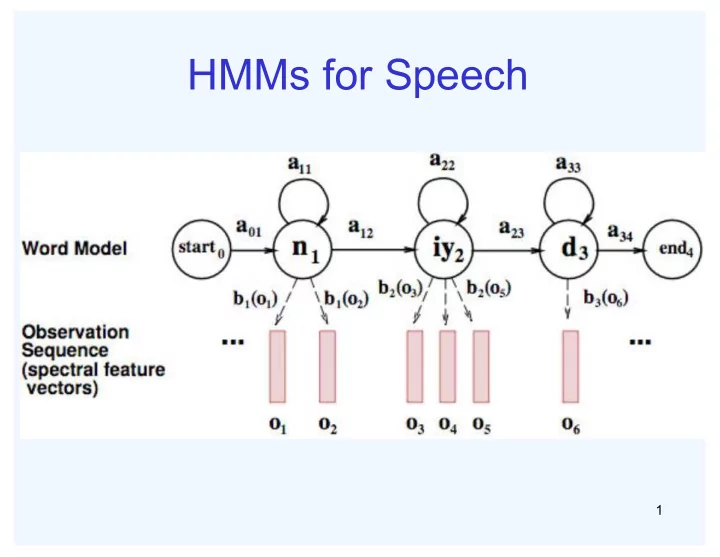
HMMs for Speech 1 Transitions with Bigrams 2 Decoding Finding the words given the acoustics is an HMM inference problem We want to know which state sequence x 1:T is most likely given the evidence e 1:T : * x argmax p x | e ( )
1
2
3
1: 1:
* 1: 1: 1: 1: 1:
T T
T T T x T T x
4
that value:
data
ML
i i
θ
ML
5
example emails, each labeled “spam” or “ham”
hand label all this data!
labels of new, future emails
used to make the ham / spam decision
6
images, each labeled with a digit
all this data!
new, future digit images
make the digit decision
AspectRation, NumLoops
7
spam/ham
diseases
8
9
generalizing well
10
Y × F
n
parameters
1Fn
i |Y
i
11
tables
the model and denoted by θ
12
p y1
p fi | c1
i
p y2
p fi | c2
i
p yk
p fi | ck
i
" # $ $ $ $ $ $ $ $ % & ' ' ' ' ' ' ' '
1 f n
divide
13
intensity is more or less than 0.5 in underlying image
→ F
0,0 = 0 F 0,1 = 0 F 0,2 =1 F 0,3 =1 F 0,4 = 0 F 15,15 = 0
p Y | F
0,0F 15,15
p F
i, j |Y
i, j
14
15
1 0.1 2 0.1 3 0.1 4 0.1 5 0.1 6 0.1 7 0.1 8 0.1 9 0.1 0.1
3,1
| p F
=
1 0.05 2 0.01 3 0.90 4 0.80 5 0.90 6 0.90 7 0.25 8 0.85 9 0.60 0.80
5,5
| p F
=
1 0.01 2 0.05 3 0.05 4 0.30 5 0.80 6 0.90 7 0.05 8 0.60 9 0.50 0.80
16
spam or ham
label all this data!
test sets
17
probability distribution p(F|Y)
p C,W
1Wn
p Wi |C
i
Word at position i, not ith word in the dictionary!
18
p C,W
1Wn
p Wi |C
i
ham 0.66 spam 0.33
|spam p W
the 0.0156 to 0.0153 and 0.0115
0.0095 you 0.0093 a 0.0086 with 0.0080 from 0.0075 …
| ham p W
the 0.0210 to 0.0133
0.0119 2002 0.0110 with 0.0108 from 0.0107 and 0.0105 a 0.0100 …
Word p(w|spam) p(w|ham) Σ log p(w|spam) Σ log p(w|ham) (prior) 0.33333 0.66666
Gary 0.00002 0.00021
would 0.00069 0.00084
you 0.00881 0.00304
like 0.00086 0.00083
to 0.01517 0.01339
lose 0.00008 0.00002
weight 0.00016 0.00002
while 0.00027 0.00027
you 0.00881 0.00304
sleep 0.00006 0.00001
19
20
p(feature, C=2) p(C=2)=0.1 p(on|C=2)=0.8 p(on|C=2)=0.1 p(on|C=2)=0.1 p(on|C=2)=0.01 p(feature, C=3) p(C=3)=0.1 p(on|C=3)=0.8 p(on|C=3)=0.9 p(on|C=3)=0.7 p(on|C=3)=0.0
21
| ham | spam p W p W
south-west inf nation inf morally inf nicely inf extent inf seriously inf …
| am | am p W sp p W h
screens inf minute inf guaranteed inf $205.00 inf delivery inf signature inf …
22
doesn’t mean we won’t see it at test time
generalization, but isn’t enough
estimates
23
p(heads)?
the probability of heads)
ML
ML
24
extra times
independently:
,0 ,1 ,100 LAP LAP LAP
,
LAP k
25
p(X)
x | y
x
26
| ham | spam p W p W
helvetica 11.4 seems 10.8 group 10.2 ago 8.4 area 8.3 …
| am | am p W sp p W h
verdana 28.8 Credit 28.4 ORDER 27.2 <FONT> 26.9 money 26.5 …
27
unknowns
smoothing to do: k,α
data
train and test on the held-out data
28
29