
SLIDE 1
MIPS Pipeline with Tomasulos Algorithm ADD ADD RS IR Issue WB - - PowerPoint PPT Presentation
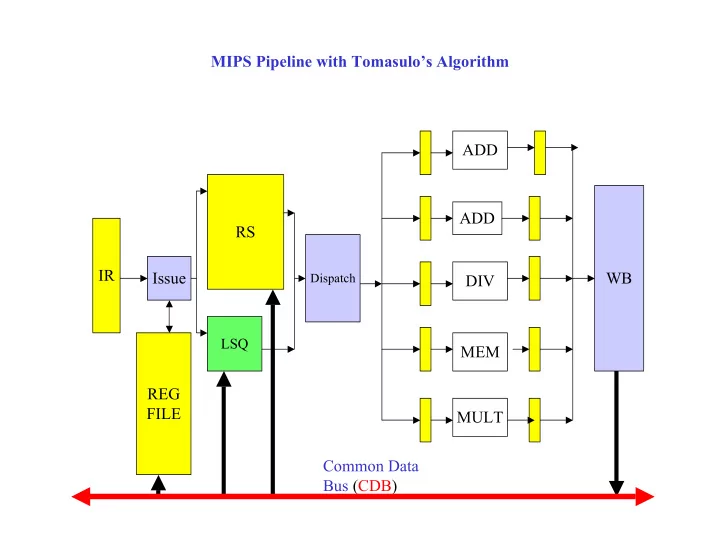
MIPS Pipeline with Tomasulos Algorithm ADD ADD RS IR Issue WB Dispatch DIV LSQ MEM REG FILE MULT Common Data Bus (CDB) Renaming Source Registers Example A: DIVD F0 , F2, F4 RAW dependency between (A,B) B: ADDD F6, F0 , F8
2
3
4
5
Issue A: DIVD F0, F2, F4
Issue B: ADDD F6, F0, F8
6
Issue D: DIVD F14, F8, F10
Issue C: SUBD F8, F10, F12
7
8
9
10
11
LOAD/STORE BUFFERS FIFO QUEUE
MEM DISPATCH ISSUE WRITE
12
13
14
15
16
&x[0] = 1000
RSB1
LQA
LQA1
RSB1
LQA1
r1 &x[0] = 1000
17
18
19
20
RSB1
RSB1
1
21
22
Cycle 7 B1: Second cycle of MUL C: Still waiting for the MUL value to be broadcast D1: ADDI instruction writes updated R1 (1004) E1: Branch instruction in EX Stage. Compares registers and finds its prediction is correct A2: Second iteration begins in IF stage. 23
RSB2
LQA2
RSB2
LQA2
24
25
LQA2
RSB2
LQA2
LQA
RSB1
RSB2
26
27
27
27
27
27
28
28
29
30