
SLIDE 1
Review of data aggregation Review of data aggregation
AVERAGE 1 Query distribution 1
49
Review of data aggregation Review of data aggregation Query - - PowerPoint PPT Presentation
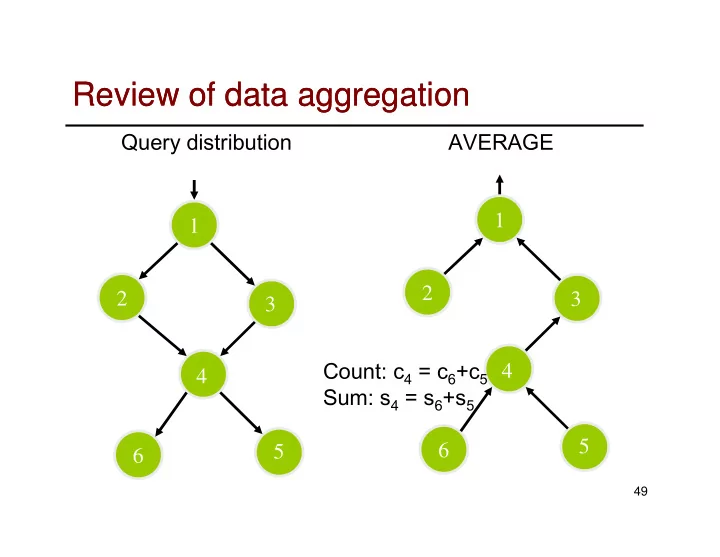
Review of data aggregation Review of data aggregation Query distribution AVERAGE 1 1 2 2 3 3 Count: c 4 = c 6 +c 5 4 4 Sum: s 4 = s 6 +s 5 5 6 5 6 49 nd problem: how to compute median? 1 nd problem: how to compute median? In a
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
2zi 2)+ E(i,jxixjzizj).
81
2)=1, E(zizj)= E(zi) E(zj)= 0.
2.
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99