
SLIDE 1
SP 800-90B Overview*
John Kelsey, NIST, May 2016
* Revised to correct some errors discovered after the presentation was given. Updated/new slides are starred.
SP 800-90B Overview* John Kelsey, NIST, May 2016 * Revised to - - PowerPoint PPT Presentation
SP 800-90B Overview* John Kelsey, NIST, May 2016 * Revised to correct some errors discovered after the presentation was given. Updated/new slides are starred. Preliminaries SP 800-90 Series, 90B, and RBGs Entropy Sources Min-Entropy
John Kelsey, NIST, May 2016
* Revised to correct some errors discovered after the presentation was given. Updated/new slides are starred.
2/40
An RBG is used as a source of random bits for cryptographic or other purposes.
90B is about how to build, test, and validate entropy sources.
DRBG mechanisms, among other things.
An entropy source is a black box that provides you entropy (unpredictable bits with a known amount of entropy) on demand.
unpredictability.
right, then X has h bits of entropy.
h = -lg( max(p1, p2, …, pk ) )
terms of min-entropy.
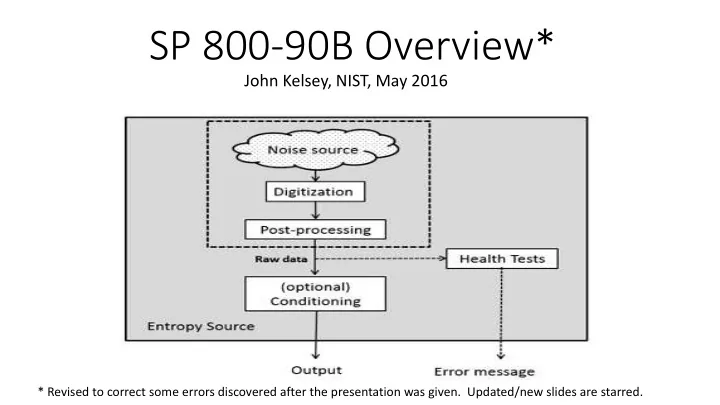
Noise Source
Where the entropy comes from
Post-processing
Optional minimal processing of noise source outputs before they are used.
Health tests
Verify the noise source is still working correctly
Conditioning
Optional processing of noise source outputs before output.
7/40
unpredictability.
actually provides the unpredictability
before they are used or tested.
that their tests detect the same failures.
entropy/bit before they are output from the entropy source.
conditioning component.
cryptographic mechanisms.
Noise Source
Where the entropy comes from
Post-processing
Optional minimal processing of noise source outputs before they are used.
Health tests
Verify the noise source is still working correctly
Conditioning
Optional processing of noise source outputs before output.
13/40
8
439 440
Estimate entropy - Non-IID track (Section 6.2) Validation fails. No entropy estimate awarded. Update entropy estimate (Section 3.1.4) Is conditioning used? Update entropy estimate (Section 3.1.5) Estimate entropy - IID track (Section 6.1) Apply Restart Tests (Section 3.1.4) Pass restart tests? Data collection (Section 3.1.1) Determine the track (Section 3.1.1) Start validation Validation at entropy estimate.
Non-IID track Yes IID track No Yes No
Figure 2 Entropy Estimation Strategy
15/40
possibly some data from conditioned outputs.
source bits.
behavior of source.
Two datasets from raw noise source samples—always required:
One dataset from conditioned outputs—sometimes required
8
439 440
Estimate entropy - Non-IID track (Section 6.2) Validation fails. No entropy estimate awarded. Update entropy estimate (Section 3.1.4) Is conditioning used? Update entropy estimate (Section 3.1.5) Estimate entropy - IID track (Section 6.1) Apply Restart Tests (Section 3.1.4) Pass restart tests? Data collection (Section 3.1.1) Determine the track (Section 3.1.1) Start validation Validation at entropy estimate.
Non-IID track Yes IID track No Yes No
Figure 2 Entropy Estimation Strategy
(optionally with post-processing)
IID = Independent and Identically Distributed
position in sequence of samples How do we determine if source is iid?
is NOT iid
8
439 440
Estimate entropy - Non-IID track (Section 6.2) Validation fails. No entropy estimate awarded. Update entropy estimate (Section 3.1.4) Is conditioning used? Update entropy estimate (Section 3.1.5) Estimate entropy - IID track (Section 6.1) Apply Restart Tests (Section 3.1.4) Pass restart tests? Data collection (Section 3.1.1) Determine the track (Section 3.1.1) Start validation Validation at entropy estimate.
Non-IID track Yes IID track No Yes No
Figure 2 Entropy Estimation Strategy
(optionally with post-processing)
IID Case:
simple statistics.
Non-IID Case:
Sample implementations of entropy estimation can be found at: https://github.com/usnistgov/SP800-90B_EntropyAssessment
estimate on the first 1,000,000 bits that result.
8
439 440
Estimate entropy - Non-IID track (Section 6.2) Validation fails. No entropy estimate awarded. Update entropy estimate (Section 3.1.4) Is conditioning used? Update entropy estimate (Section 3.1.5) Estimate entropy - IID track (Section 6.1) Apply Restart Tests (Section 3.1.4) Pass restart tests? Data collection (Section 3.1.1) Determine the track (Section 3.1.1) Start validation Validation at entropy estimate.
Non-IID track Yes IID track No Yes No
Figure 2 Entropy Estimation Strategy
(optionally with post-processing)
* This is leaving out some details. See the full
90B draft for the full picture.
apparent when examining many sequences generated by a source across restarts.
Restart dataset is a 1,000 x 1,000 matrix of samples
Use the matrix to generate two additional datasets:
sample sequence
1,000,000 sample sequence
should appear in a column or row.
H[final] = min(H[original],H[submitter],H[binary],H[r],H[c])
8
439 440
Estimate entropy - Non-IID track (Section 6.2) Validation fails. No entropy estimate awarded. Update entropy estimate (Section 3.1.4) Is conditioning used? Update entropy estimate (Section 3.1.5) Estimate entropy - IID track (Section 6.1) Apply Restart Tests (Section 3.1.4) Pass restart tests? Data collection (Section 3.1.1) Determine the track (Section 3.1.1) Start validation Validation at entropy estimate.
Non-IID track Yes IID track No Yes No
Figure 2 Entropy Estimation Strategy
row, column,
entropy estimate for noise source.
sample in an arbitrary sequence of values.
support this...
and what expertise we can require from labs. This approach is the best we know how to do given existing constraints.
Noise source is validated by examining documentation and entropy estimation. We still need to validate:
29/40
functions
Noise sources can be fragile. Thus, all entropy sources MUST have health tests.
failure of the noise source that won’t be detected!
used unless the test detects a problem
failure here.
may be used for anything.
more common in output than expected.
The repetition count test is an updated version of the “stuck test.”
important (for example, 2-50).
repetitions were seen
The Adaptive Proportion Test tries to detect when one particular value has become much more common than expected.
choose cutoff value C.
appears in the whole window.
when writing this document.
they meet the requirements: (H = entropy/sample of noise source)
detect this with high probability.
detect this with acceptable probability.
their tests meet these requirements.
continuous health tests running. The samples CANNOT be used until the testing is complete.
samples.
41/40
resources?