
SLIDE 1
Winter 2006 CSE 548 - Dataflow Machines 1
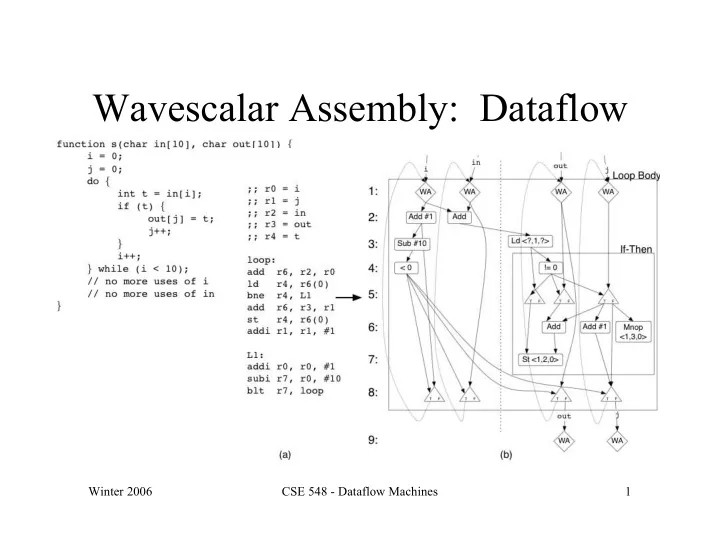
Wavescalar Assembly: Dataflow Winter 2006 CSE 548 - Dataflow - - PowerPoint PPT Presentation
Wavescalar Assembly: Dataflow Winter 2006 CSE 548 - Dataflow Machines 1 Wavescalar Assembly: Format Wavescalar is an extension of the Alpha ISA RISC (more or less) Register to register becomes PE to PE
Winter 2006 CSE 548 - Dataflow Machines 1
Winter 2006 CSE 548 - Dataflow Machines 2
Winter 2006 CSE 548 - Dataflow Machines 3
– You have infinite “registers” ldq a, addr, 0 ldq b, addr, 8 addq c, a, b
– The linker resolves symbols (if possible) L0: ldq { }, addr, 0 ldq ^L1:2, addr, 8 L1: addq c, ^L0:0, { }
Winter 2006 CSE 548 - Dataflow Machines 4
Winter 2006 CSE 548 - Dataflow Machines 5
http://www.cs.cmu.edu/afs/cs.cmu.edu/academic/class/15740- f98/public/doc/alpha-guide.pdf
– add, sub, mul, div, … – Long word (32 bit) arithmetic addl {outputs}, {inputAs}, {inputBs} – Quad word (64 bit) arithmetic addq {outputs}, {inputAs}, {inputBs}
– cmple, cmpeq, …
– and, bis, xor, …
Winter 2006 CSE 548 - Dataflow Machines 6
Winter 2006 CSE 548 - Dataflow Machines 7
Winter 2006 CSE 548 - Dataflow Machines 8
Winter 2006 CSE 548 - Dataflow Machines 9
Winter 2006 CSE 548 - Dataflow Machines 10
Winter 2006 CSE 548 - Dataflow Machines 11
– Wave advance (wa)
– Canonical wave advance (cwa)
wave
Winter 2006 CSE 548 - Dataflow Machines 12
Winter 2006 CSE 548 - Dataflow Machines 13
– rho (split): conditional rho {T-output}, {F-output}, {value}, {predicate} – phi (join): speculative phi {output}, {T-value}, {F-value}, {predicate}
+ predicate T path F path value + predicate T path F path value
Winter 2006 CSE 548 - Dataflow Machines 14
Winter 2006 CSE 548 - Dataflow Machines 15
– Indirect send, indirect receive – Dynamic resolution is fairly slow
Winter 2006 CSE 548 - Dataflow Machines 16
Winter 2006 CSE 548 - Dataflow Machines 17
Winter 2006 CSE 548 - Dataflow Machines 18
Winter 2006 CSE 548 - Dataflow Machines 19